pandas DataFrame rolling 后的 apply 只能处理单列,就算用lambda的方式传入了多列,也不能返回多列 。想过在apply function中直接处理外部的DataFrame,也不是不行,就是感觉不太好,而且效率估计不高。
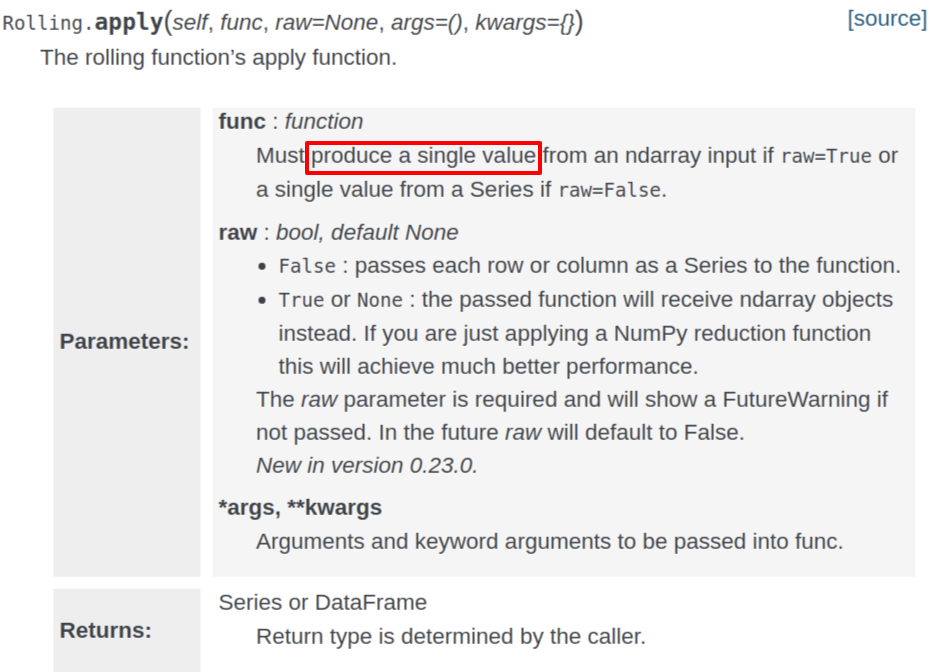
这是我在写向量化回测时遇到的问题,很小众的问题,如果有朋友遇到可以参考我这个解决方案。内容来自于 StockOverFlow,我做了一下修改。
相对于传统的rolling,这个roll默认就是min_periods = window,然后只支持二维的
还有点要注意,就是apply function里面传进来的DataFrame是有多级索引的
import pandas as pd
from numpy.lib.stride_tricks import as_strided as stride
dates = pd.date_range('20130101', periods=13, freq='D')
df = pd.DataFrame({'C': [1.6, 4.1, 2.7, 4.9, 5.4, 1.3, 6.6, 9.6, 3.5, 5.4, 10.1, 3.08, 5.38]}, index=dates)
df.index.name = 'datetime'
def roll(df: pd.DataFrame, window: int, **kwargs):
"""
rolling with multiple columns on 2 dim pd.Dataframe
* the result can apply the function which can return pd.Series with multiple columns
Reference:
https://stackoverflow.com/questions/38878917/how-to-invoke-pandas-rolling-apply-with-parameters-from-multiple-column
:param df:
:param window:
:param kwargs:
:return:
"""
# move index to values
v = df.reset_index().values
dim0, dim1 = v.shape
stride0, stride1 = v.strides
stride_values = stride(v, (dim0 - (window - 1), window, dim1), (stride0, stride0, stride1))
rolled_df = pd.concat({
row: pd.DataFrame(values[:, 1:], columns=df.columns, index=values[:, 0].flatten())
for row, values in zip(df.index[window - 1:], stride_values)
})
return rolled_df.groupby(level=0, **kwargs)
def own_func(df):
"""
attention: df has MultiIndex
:param df:
:return:
"""
return pd.Series([df["C"].mean(), df["C"].max() + df["D"].min()])
测试运行结果:
print(df)
C
datetime
2013-01-01 1.60
2013-01-02 4.10
2013-01-03 2.70
2013-01-04 4.90
2013-01-05 5.40
2013-01-06 1.30
2013-01-07 6.60
2013-01-08 9.60
2013-01-09 3.50
2013-01-10 5.40
2013-01-11 10.10
2013-01-12 3.08
2013-01-13 5.38
df[["C_mean", "C+D"]] = roll(df, 5).apply(own_func)
print(df)
C D C_mean C+D
datetime
2013-01-01 1.60 5.40 NaN NaN
2013-01-02 4.10 3.20 NaN NaN
2013-01-03 2.70 8.80 NaN NaN
2013-01-04 4.90 3.60 NaN NaN
2013-01-05 5.40 12.60 3.740 8.6
2013-01-06 1.30 9.30 3.680 8.6
2013-01-07 6.60 11.80 4.180 10.2
2013-01-08 9.60 8.90 5.560 13.2
2013-01-09 3.50 4.60 5.280 14.2
2013-01-10 5.40 1.90 5.280 11.5
2013-01-11 10.10 0.10 7.040 10.2
2013-01-12 3.08 8.02 6.336 10.2
2013-01-13 5.38 3.80 5.492 10.2
测试发现 stride的速度很快,不过concat的速度很慢,pandas的各路操作确实是慢,不知有什么方法能优化一下
pandas concat group 这一路操作太慢了,无法接受,又改了一版纯numpy的,速度快很多
def roll_np(df: pd.DataFrame, apply_func: callable, window: int, return_col_num: int, **kwargs):
"""
rolling with multiple columns on 2 dim pd.Dataframe
* the result can apply the function which can return pd.Series with multiple columns
call apply function with numpy ndarray
:param return_col_num: 返回的列数
:param apply_func:
:param df:
:param window
:param kwargs:
:return:
"""
# move index to values
v = df.reset_index().values
dim0, dim1 = v.shape
stride0, stride1 = v.strides
stride_values = stride(v, (dim0 - (window - 1), window, dim1), (stride0, stride0, stride1))
result_values = np.full((dim0, return_col_num), np.nan)
for idx, values in enumerate(stride_values, window - 1):
# values : col 1 is index, other is value
result_values[idx,] = apply_func(values, **kwargs)
return result_values
def own_func_np(narr, **kwargs):
"""
:param narr:
:return:
"""
c = narr[:, 1]
d = narr[:, 2]
return np.mean(c), np.max(c) + np.min(d)
测试运行结果:
return_values = tableRollNp(df, own_func_np, 3, 2)
df["C_mean_np"] = return_values[:,0]
df["C+D_np"] = return_values[:,1]
print(df)
C D C_mean_np C+D_np
datetime
2013-01-01 1.60 5.40 NaN NaN
2013-01-02 4.10 3.20 NaN NaN
2013-01-03 2.70 8.80 2.800000 7.3
2013-01-04 4.90 3.60 3.900000 8.1
2013-01-05 5.40 12.60 4.333333 9.0
2013-01-06 1.30 9.30 3.866667 9.0
2013-01-07 6.60 11.80 4.433333 15.9
2013-01-08 9.60 8.90 5.833333 18.5
2013-01-09 3.50 4.60 6.566667 14.2
2013-01-10 5.40 1.90 6.166667 11.5
2013-01-11 10.10 0.10 6.333333 10.2
2013-01-12 3.08 8.02 6.193333 10.2
2013-01-13 5.38 3.80 6.186667 10.2
结果和pandas那一版一样。但是中间处理 index,结果什么的需要自己切一下numpy二维矩阵,这个应该是小case吧。
回头看看代码,其实里面最重要的函数就是stride,这也是numpy的核心,为什么速度这么快的核心。numpy的数据在内存中是连续存储的,所以numpy的底层操作是直接进行对内存进行寻址访问,stride告诉我们加一行,加一列需要加的内存地址是多少。这样访问是飞快的。
所以对numpy操作时,进行slice操作是对原数组进行的操作,速度快;尽量不要重新生存数组,尽量不要做类似append的操作,这样内存会反复拷贝,就慢了。
我改的这几个函数通用性不高,大家可以自己diy一下。
Comments
comments powered by Disqus