两个Dataframe都是时间index,但是时间范围不一样,而且列名不一样,想组合在一块儿,用Nan来填充
# 这种方式只能应用于数字,注意add的方式一样x,y的数字是会相加的,而下面的concat不会,会出现同名列
# 注意,如果某个index df2中没有,是会以Nan方式填充,并不会以fill_value的值填充
df1.add(df2, fill_value=0)
# 这种方式通用性更强 axis=1表明是列左右拼接 0行上下拼接,key不会自动重合
pd.concat([df1, df2], axis=1)
如果有一些Nan可以用前面的值顺延来填充可以用fillna(method='ffill'),在做投资品种分析时多品种(各品种交易时间会有差别)组合时会用得到
其实不复杂,0或者是1都代表两种操作: 1. label取值:0 按行label取,1 按列label取 2. 扫描所有值:0 按列上下扫描,1 按行左右扫描
总结一下,0代表上下,1代表左右
Dataframe 持久化
-
mongodb存储json,但是有大小限制
-
最方便的是hdf5,to_hdf或者HDFStore,速度快,操作方便操作示例
计算收益率
简单收益率
df['close'].pct_change().dropna()
(df['close']/df['close'].shift(1)).dropna() - 1
(df['close'].diff()/df['close'].shift(1)).dropna()
对数收益率
np.log(df['close']/df['close'].shift(1)).dropna()
# 这种方法运用了log里面除拆出来就是减法的规则
np.log(df['close']).diff().dropna()
matplotlib 图形的横轴
只能用日期或者数字,这样是连续的,非连续的都不行
相关系数
dataframe.corr(x)
# 一般取结果数组里面的[0,1]用作相关系数[这里有样例](https://www.ricequant.com/community/topic/2039//3),如果打不开就点击"克隆研究"
np.corrcoef(x,y)
# 上面的是常规相关系统
# spearman相关系数,会先把数据做rank再做计算,如果变化量不一样,方向相同,这样算出来的相关性会比常规的要大
import scipy.stats as stats
r_s = stats.spearmanr(X,Y)
r_s[0] # 相关系统-1~1
r_s[1] # p-value 小于0.05说明相关,大于0.05说明不相关
经测试,上面两个函数计算的数值是一样的
lagged 相关
这算是相关系数的一个子项目,传统的相关系数有一个问题就是一旦某一组数据有延迟就不能识别他们的相关性
其实是有方法的,时间序列分析方法里面有一个 VAR,向量自回归就可以进行检测,还有一种方法格兰杰因果检验
from statsmodels.tsa.stattools import grangercausalitytests
grangercausalitytests(df[["y", "x"]], maxlag=10)
其实回头想想,自己写一个也很容易,循环一下测试传统相关系数就行
SearchSorted
这个函数 numpy 中有,在 pandas 中也有,当然 pandas 应该就是用的 numpy 实现的
原理很简单,其实就是把查找的元素假装插入数组后的 index(从0开始)。如:[1,2,3,4,5,6] 查找 4, 这样可以放在3和4中间,结果是3,放在4和5中间,结果是4。是3或者4由参数side控制。当然最好原始数组排过序,不然会发生什么事情可能是不可预知的。
我其实经常碰到这个场景,金融时间序列数据,我想找一个离某个时间点最近的数据,但是这个时间又没有存在于数据中,,所以用.loc是定位不到的,这时候就用到 searchsoreted 函数了
具体怎么用,看详细解释吧
取某些行,但是索引里面还有不存在的key
reindex(key_list).dropna()
把原来的索引取消,转为正常数据列
reset_index(drop=False)
时间序列做resample
1.不要在原df上增加列去存储新数据,因为index不一样,要给一个新的df
2.国内商品期货的分割时间为21:00
df.resample('24H', base=20, label='right').last().dropna().resample('D').last().dropna()
3.去掉周6的数据
# 过滤掉周6的数据
rest_day_filter = pd.date_range(df.index[0], df.index[-1], freq="W-SAT")
df[df.index.isin(rest_day_filter)] = np.nan
df = df.dropna()
boolean过滤器的使用
尽量不要使用老方法了,如:
df[df[filter]][poxA_idx] = 1
要用loc:
df.loc[df['sig_positive'], posA_idx] = 1
过滤器是支持逻辑运算的
# pandas
# We can add multiple boolean conditions by using the logical operators &, |, and ~ (and, or, and not, respectively) again!
prices.loc[(prices.MCD > prices.WFM) & ~prices.SHAK.isnull()].head()
# numpy 下的逻辑运算
np.logical_and(,)
np.logical_or(,)
fillna 的坑
df_mean = df.groupby("industryID1").mean()
df.fillna(df_mean, inplace=True)
主要是针对参数为Dataframe的使用,这时 df_mean 的 key 就为 industryID1
- df 要把 index 设置为 industryID1
- df 要对按 industryID1 进行排序
上述条件缺一不可
去inf值
原以为dropna可以去inf值,但是不行,正确做法是
df.replace([np.inf, -np.inf], np.nan).dropna()
np.isfinite 可以判断np.inf,np.nan这些值
weight 的和为1
其实很简单,但是我一下真没想出来
比如 w1 = 1, w2 = 8, w3 = 15
标准化w1+w2+w3=1,其实就是
total = w1+w2+w3
w1 = w1/total
w2 = w2/total
w3 = w3/total
# 用pandas或者numpy就更简单
w = np.array([1,8,15])
w = w/np.sum(w)
自回归
pandas中有一个函数画出自回归的曲线,极为方便
from pandas.plotting import autocorrelation_plot
series = ...
autocorrelation_plot(series)
下面可以达到同样的效果
from statsmodels.graphics.tsaplots import plot_pacf,plot_acf
plot_acf(ts)
plt.show()
随机选择 随机打乱
np.random.permutation 把一个价格序列随机打乱顺序,元素和原样本空间一样,只是序列不一样
np.random.choice 在一个样本随机再采样,是原样本空间的子集
寻找前N个最大值的索引 numpy
np.argpartition(array, k)
其实这个函数的作用是把topk的数放到一边,另外的数放在一边,做快排时使用的
这样我们就可以把topk的索引拿出来,再排序啥的
array = np.array([10, 7, 4, 3, 2, 2, 5, 9, 0, 4, 6, 0])
index = np.argpartition(array, -5)[-5:]
index
array([ 6, 1, 10, 7, 0], dtype=int64)
np.sort(array[index])
array([ 5, 6, 7, 9, 10])
把数组内的数值控制在(limit_min, limit_max)内 numpy
np.clip(array, limit_min, limit_max)
比如把一数组内的值控制在[-1, 1]内,这样大于1的值会变成1,大小-1的值会变成-1
#Example-1
array = np.array([10, 7, 4, 3, 2, 2, 5, 9, 0, 4, 6, 0])
print (np.clip(array,2,6))
[6 6 4 3 2 2 5 6 2 4 6 2]
#Example-2
array = np.array([10, -1, 4, -3, 2, 2, 5, 9, 0, 4, 6, 0])
print (np.clip(array,2,5))
[5 2 4 2 2 2 5 5 2 4 5 2]
找出符合条件的数值 numpy
符合条件的值提取出来,其实在pandas很简单,上面提到过,boolean数组的使用
df.loc[df["return"]>0.03, "return"]
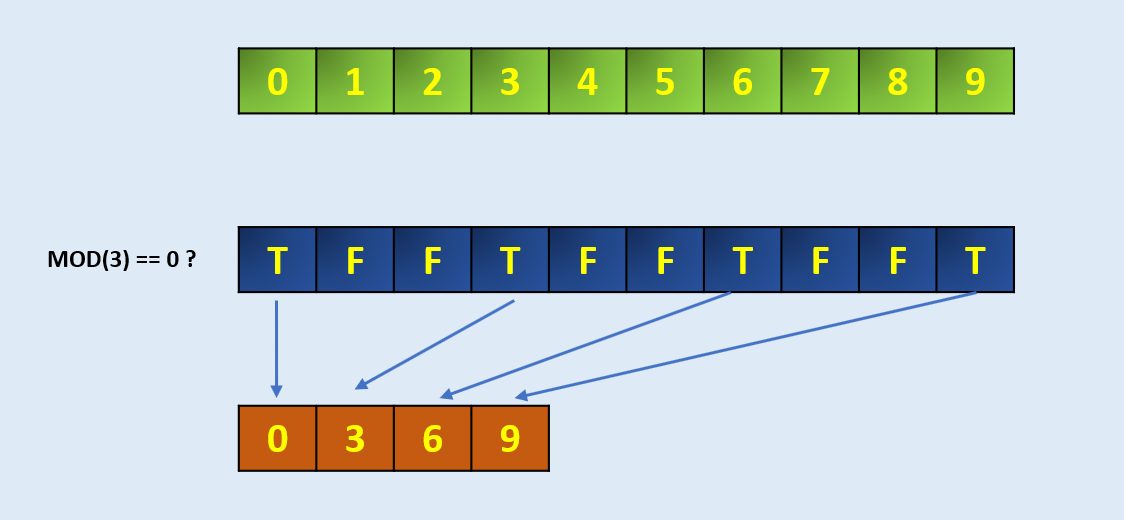
arr = np.arange(10)
arr
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# Define the codition, here we take MOD 3 if zero
condition = np.mod(arr, 3)==0
condition
array([ True, False, False, True, False, False, True, False, False,True])
np.extract(condition, arr)
array([0, 3, 6, 9])
也可以使用逻辑运算符
np.extract(((arr > 2) & (arr < 8)), arr)
array([3, 4, 5, 6, 7])
把出在a数组但是没有b数组中的元素并去重 numpy
np.setdiff1d(array, a, b)
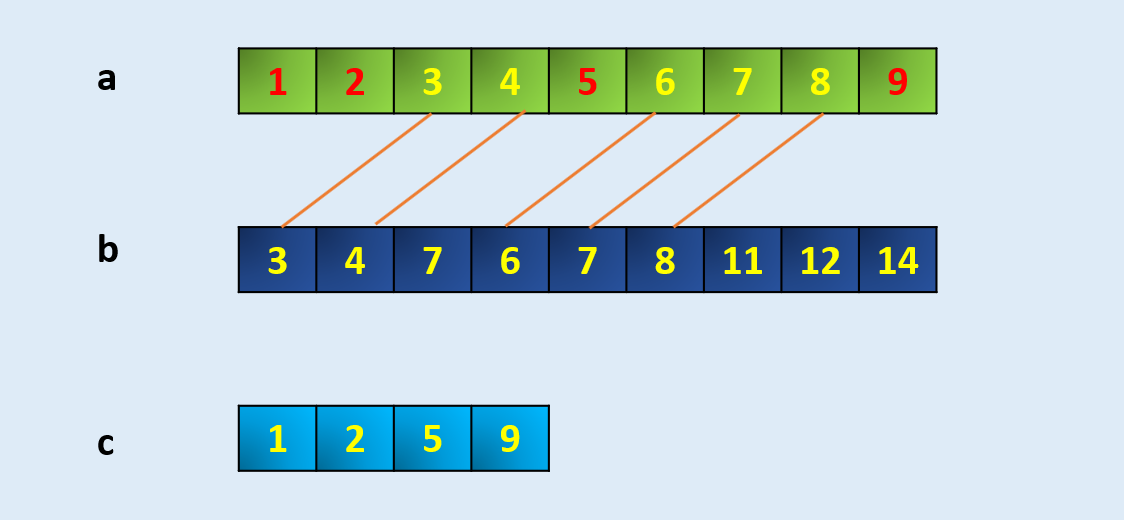
a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
b = np.array([3,4,7,6,7,8,11,12,14])
c = np.setdiff1d(a,b)
c
array([1, 2, 5, 9])
numpy.dot() 与 协方差矩阵
一维时是内积,二维时是矩阵运算
因为一直对协方差矩阵有些理解不深,请看quantopian 协方差在投资组合中的运用最后的一节
在投资组合方差计算算一个案例,以后再补充期货案例
参考:现代投资组合理论
numpy 初始化 datetime 数组
dt_array = np.zeros(buffer_size, dtype='datetime64[s]')
代码中的[s]表示精度是second
Comments
comments powered by Disqus