请参考:lee hongyi 2007 lec 9-1
更换activation function
sigmoid的缺点: - 在多层NN时,backpropagation会有点问题 - sigmoid 的特性决定,输入的变化很大时,其实越到后面输出的变化就越小
relu:
现在是主力激活函数,虽然relu本身是线性函数,但是多层复合组合起来并不是线性模型
注意: relu是可能导致某节点weight为0的,减慢学习速率是可以缓解这个问题的
maxout:
这个是动态的激活函数,貌似很厉害,再云深入了解一下。
Adaptive learning rate
自适应学习速率
adagrad 还不错,但是鲁棒性不强
rmsprop(froot mean square prop) 推荐,带权重自动调整learning rate
adam,最后上场,带动量特性,现在最常用。adam = Rmsprop + momentum
early stopping
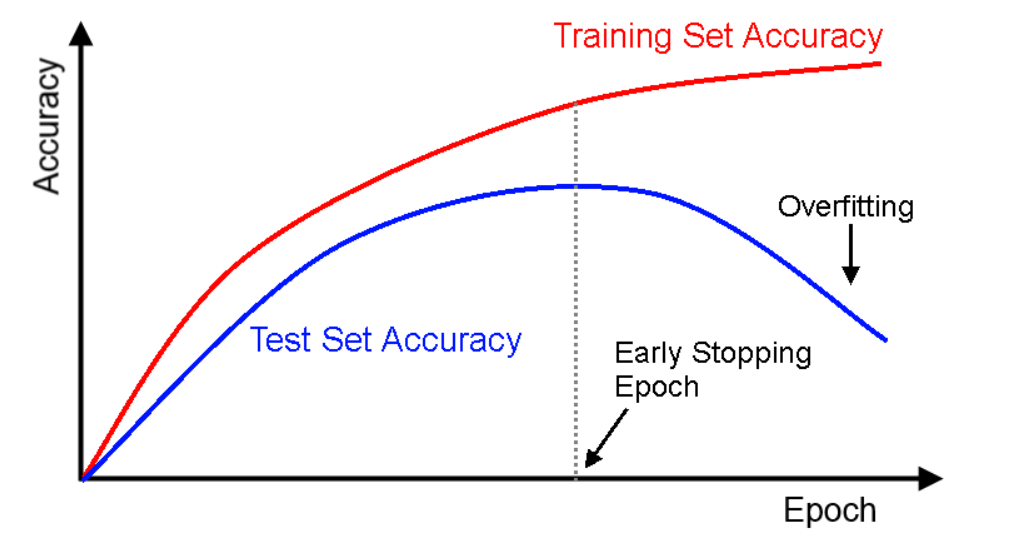
一张图解释一切,其实就是传统机器学习方法的方差和偏差均衡的问题。调整的参数是epoch的轮数。
在DNN上做cross validation是否可行?
regulization
在传统的统计学方法就是岭回归和lasso回归,岭是l2,lasso是l1,这个貌似用在DNN上效果不如在传统方法上明显
Dropout(随机丢掉一些神经元)
这不就是传统方法上的bagging吗?
batch normalization
相关解释 解决梯度爆炸
Comments
comments powered by Disqus