测试环境:ubuntu 18.04 + vscode 1.34.0
数据获取:tushare
我们采用了中国平安(601318.SH) 2010~2019年的日K线
数据获取
这里用的是tushare,能提供行情,财务等很多各类的数据(Tick暂时没有)。除了下面这张图片上的数据外,还有资金流向,龙虎榜,十大股东,大宗交易等。这么多种类的数据做为分析股价的因子还是不错的,以后得好好挖掘一下。点击这里可以直接注册。

我这里用到了前复权的日线数据。对应的API为pro_bar,文档请点击Tushare pro_bar 函数文档
ts_code 待查询的股票代码 adj 复权类型(只针对股票):None未复权 qfq前复权 hfq后复权 , 默认None start_date 数据开始日期 end_date 数据结束日期
import tushare as ts
ts.set_token("********")
# 获取前复权的日线数据
df = ts.pro_bar(ts_code="601318.SH", adj='qfq', start_date="20100101", end_date="20190601")
df.head()
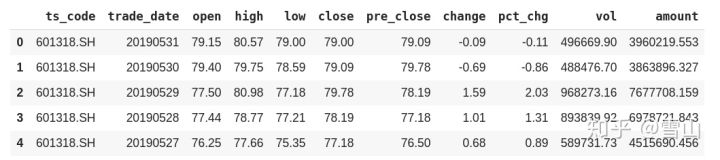
tushare获取10年的数据还是挺快的,不错。数据准备好了,下面开始实验。
1. 延迟股价预测陷阱
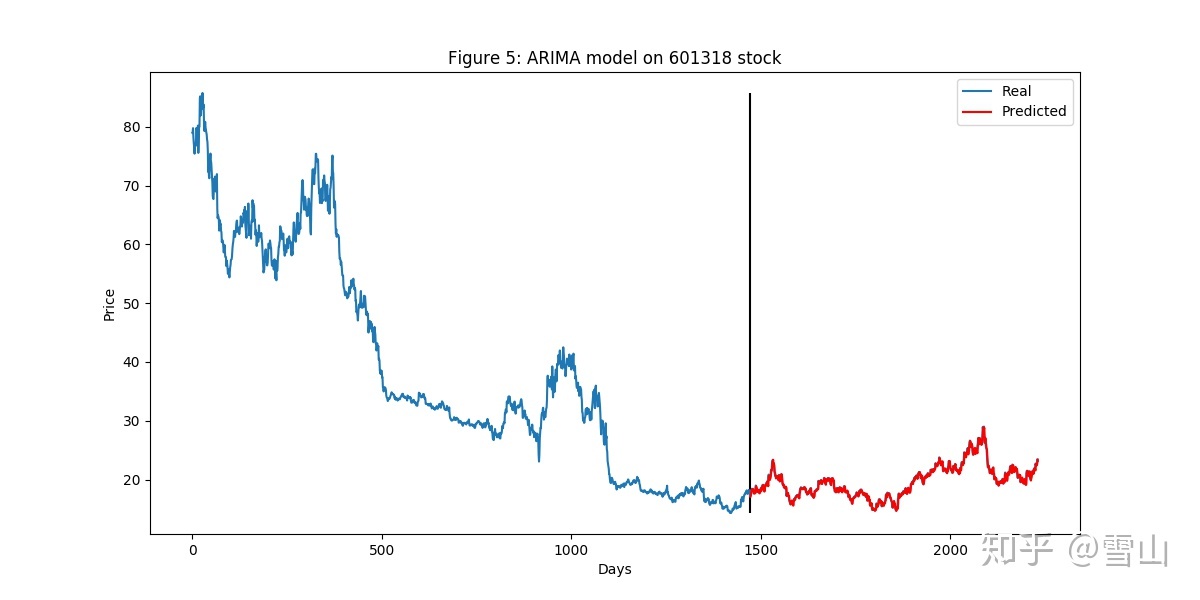
竖线左边是训练集,右边是测试集。数据完全真实,而且没用未来数据,测试集上预测和真实结果精确度如下:
Test MSE: 0.176 R2: 0.98 Corr: 0.9880012959390138
我去,R2为0.98,我了个擦,一个ARIMA模型就可以印钱了,曾经用未来数据预测出50% R2收益率的我感觉这怎么想也不科学。我本能的做了另外一个实验,看细节,其实我当时是把图片下载下来,用图片查看器放大看的,哈哈。这里我把数据量减少就可以看到里面的细节了
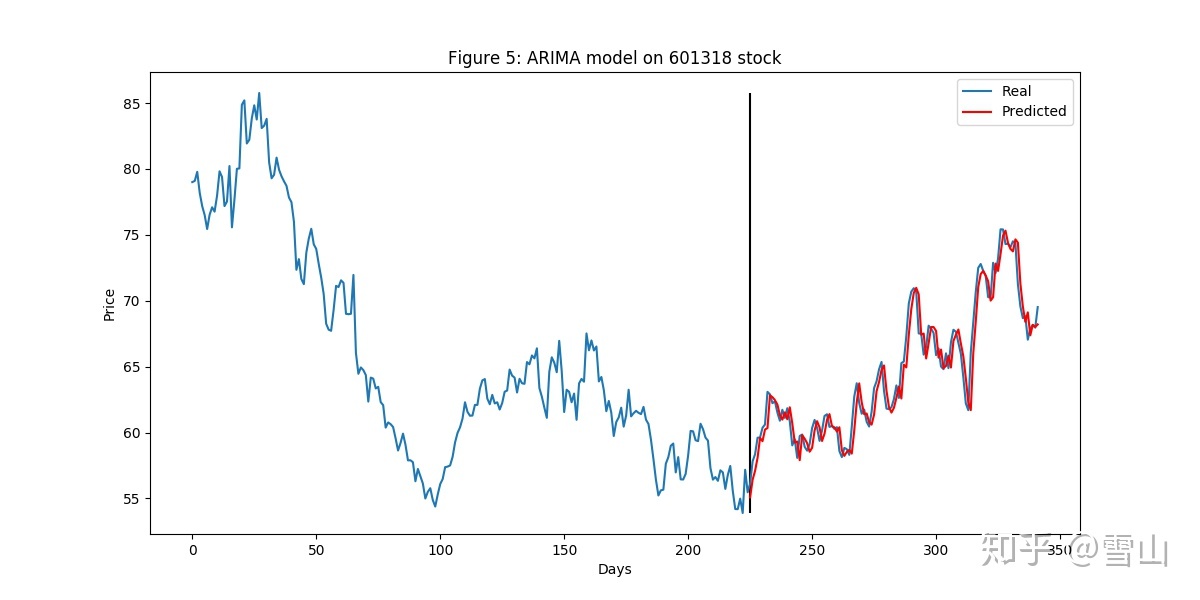
这下发现问题了吧,第一张图太完美是因为数量量大,把一些细节给盖过去了。这里可以看出,预测明天的股价其实就是用的近似今天的股价:\( p_{t+1}=p_t \)
这时候会有人问,延迟预测不要紧啊,我做如下交易:
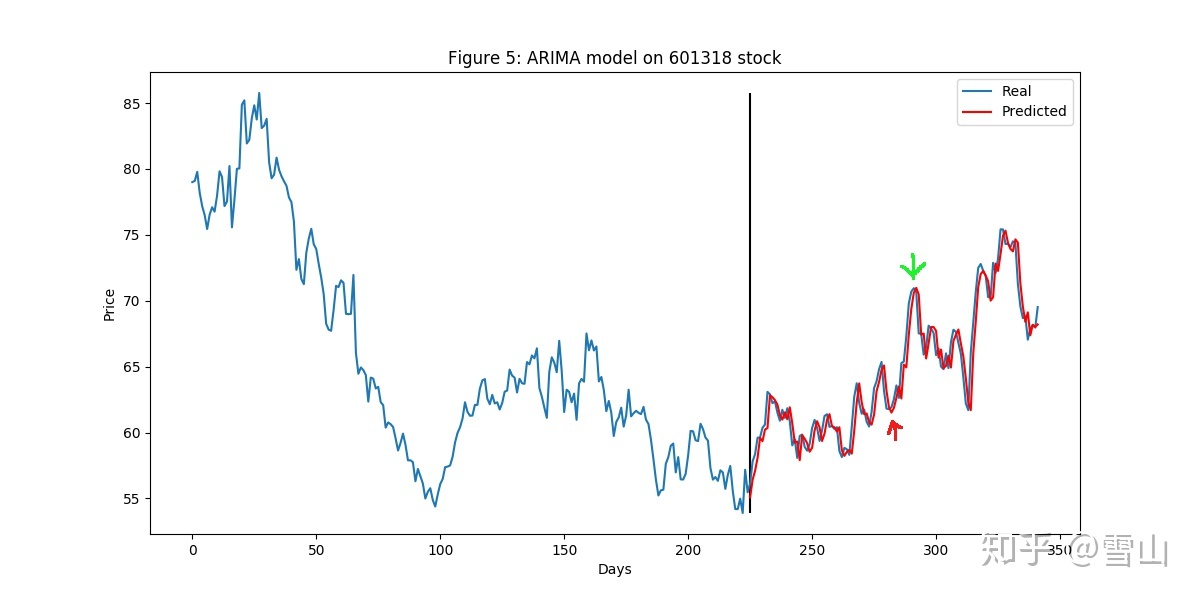
很有道理的样子,这还是一台印钱机,我们来看看代码:
X = series.values
size = int(len(X) * 0.66)
train, test = X[0:size], X[size:len(X)]
history = [x for x in train]
predictions = list()
for t in range(len(test)):
model = ARIMA(history, order=(5, 1, 0))
model_fit = model.fit(disp=0)
output = model_fit.forecast()
yhat = output[0][0]
obs = test[t]
predictions.append(yhat)
history.append(obs)
可从这段代码看出其实近似于是一个online学习的模型,只是每次都重新拟合所有的train数据。每天收市后把以前所有的历史数据用ARIMA模型拟合一下,再预测明天的股价,所以根本没机会看到5天后的股价,所以上图中的买卖操作是不可行的。
一台这么完美的印钱机就这么没了,有点可惜。
我们再仔细分析一下上面这一通操作,ARIMA模型能预测股价吗?当然是不行的,时间序列最开始讲的就是弱平稳序列(期望和方差一直保持恒定)(PS:我这个半路出家的人还没有学习时序分析这套东西),这是时间序列分析的基础,股价数据不是平稳序列,用ARIMA模型做股价预测这是不科学的。
我觉得我们还是用股价的收益率做预测的标的,我现在对用机器学习预测收益率,对是否要求收益率平稳,还未进行过多的研究,多方不同的意见我都见过。
在另外的文章中提到过股价的差分阶数也是一个需要注意的地方,多少价,整数阶,分数阶,出来的序列是否为平稳序列,这个建议还是细致的研究一下,像我之前做ML预测基本不做检测。。这是不好的。
这里我就用log return做为预测标的,再来计算一下R2:
R2: -0.022689612264394476
代码如下:
cdf = pd.DataFrame({"y": test, "predict_y": predictions})
cdf["predict_y"] = np.log(cdf["predict_y"]/cdf["y"].shift(1))
cdf["y"] = cdf["y"].pct_change()
cdf = cdf.replace([np.inf, -np.inf], np.nan)
cdf.dropna(inplace=True)
r2 = r2_score(cdf["y"], cdf["predict_y"])
这里有个细节要注意一下就是:
# 错误
cdf["predict_y"] = np.log(cdf["predict_y"]/cdf["predict_y"].shift(1))
# 正确
cdf["predict_y"] = np.log(cdf["predict_y"]/cdf["y"].shift(1))
因为每天收市后我们都能得到正确的收盘价,再用预测的错误的收盘价做计算就有问题了。然后,看到R2成负的,我也就放心了。
2.收益率换算成股价
此案例为NN预测股价
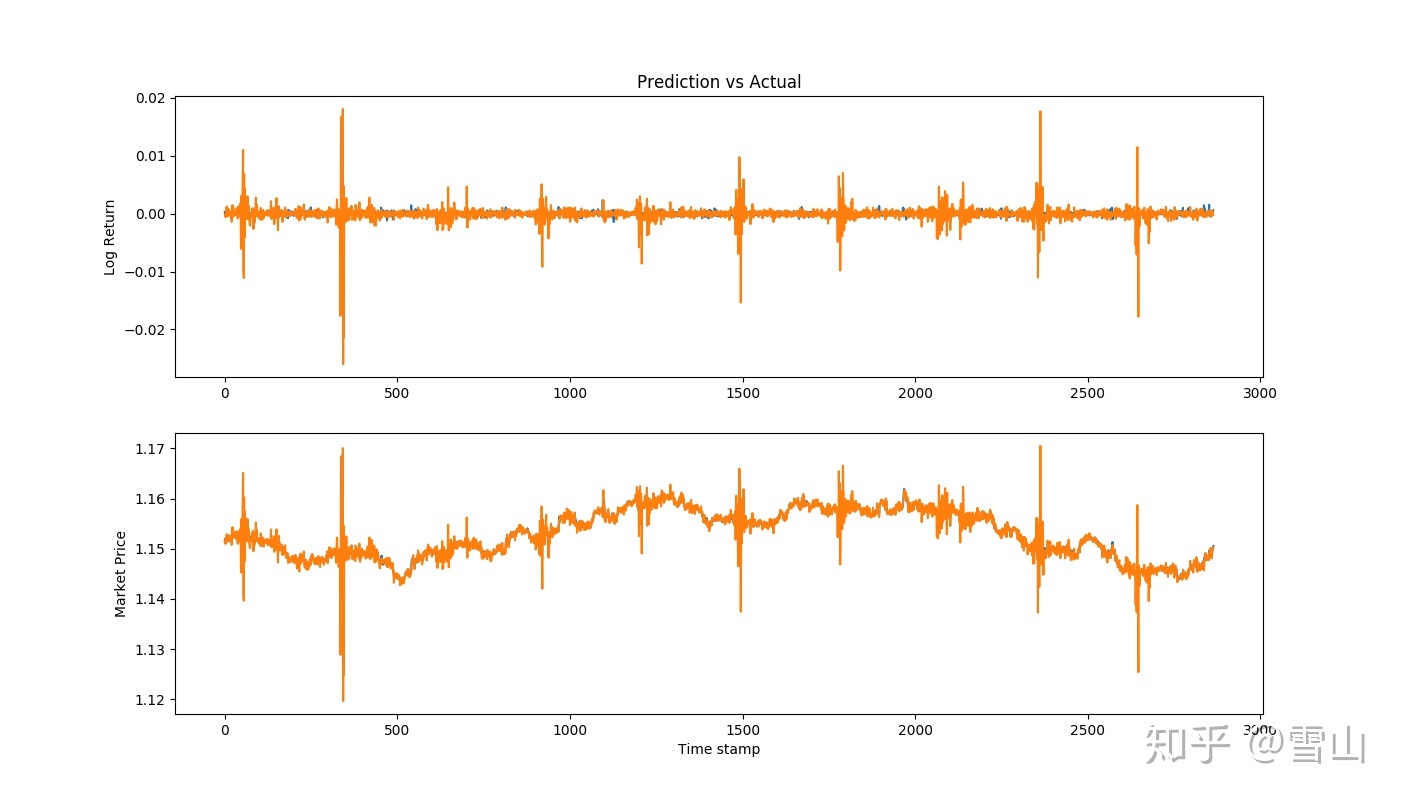
看Markiet Price那一栏,预测为黄色,真实为蓝色,一看预测和真实基本一样啊,除了有几个时刻有点异常的波动之外,印个钱应该没问题吧。
现看看相关的预测准确度测量:
Predicted Price r^2 value: 0.865376551474062 Predicted return r^2 value: -0.027964975056341768
看到这个结果和上面一样也就放心了,return的R2为负的,这个模型也是用不了的。
那为什么Market Price的预测这么准确呢?看看这个模型中的这一段代码:
# 真实价格
price = ....
predicted_data = []
predicted_price = []
for i in range(len(test_data)):
prediction = model.predict(np.reshape(test_data[i], (1, 20)))
predicted_data.append(prediction)
price_pred = np.exp(prediction)*price[i]
predicted_price.append(price_pred)
price_pred = np.exp(prediction)*price[i]
看到这一行,就知道了,其实模型是预测的收益率,只是变换成了股价,是用每天的真实收盘价乘以收益率得出明天的股价,从return R2可以得知,其实大部分的预测都是不准确的。
为什么看起来这么像印钱机呢?因为股价每天的变动太小了,1%,2%,而且计算股价的基点又是真实价格,所以有一点点偏差根本看不出来,这也是为什么股价预测的R2达到了0.86
总结
上面两个案例是我最近碰到的,都是在国外的。第一个案例是整个模型中的特征工程的一个小块而已,完整模型没有放出代码无法验证,该模型的追捧者还不少,但是直接给股份做时序分析这一点我觉得要值得怀疑吧。
第二个就是一个完整的模型,作者只在页面上给出了股价预测的R2,很吸引眼球。return R2是要把代码下载下来自己跑一下才会显示。
这其中有一个作者的学历非常显赫,像我这种半路出家才学ML的很容易被一张Market Price Predicted Graph加作者的学历所迷惑。
希望刚入ML的朋友们谨慎看待印钱机的产生,保持自己的判断,因为把印钱机放在网上或者论文里面这并不科学。
Comments
comments powered by Disqus