其实我刚刷完ISL的时候我就有种相见恨晚的感觉,但是还是把一些基础完全刷完了再动工,因为这样可能会思路多一些吧。ESL我暂时不打算刷了,现在是实用性的,等需要深入某个算法的时候再看也不迟。
方差(variance)和偏差(bias)
方差:其实就是波动,比如好的枪打在靶上,方差小,集中在小圈里面,差的枪,集中在大圈里面。
偏差:其实就是离靶心有多远。
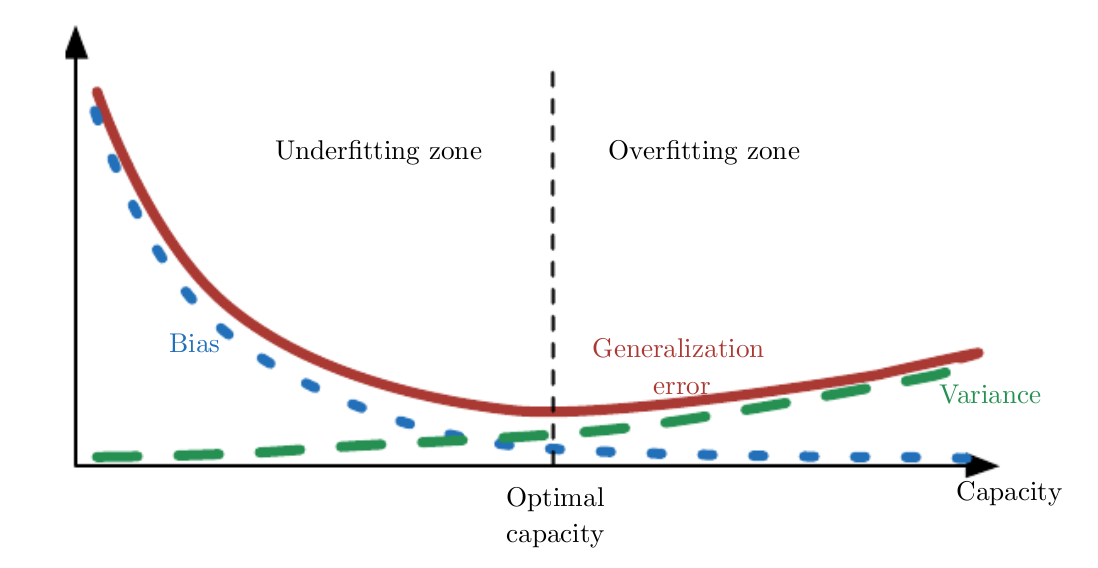
偏差可以用train set的原始值和模型预测值做一个统计,所有差值的平方除以样本个数(MSE)。
方差可以用test set上的MSE来进行统计,在最低点前是不准的,但是也没有特别好的方法统计。
集成学习的方法如bagging用到了一个点:多组观测值预测出来的值做平均会大大降低方差(test set),最重要的是会大在降低偏差,多个离靶心远的值的平均离靶心越来越近(ISL p45)。
判别模型和生成模型
参考资料 (也可参考lee hongyi 2007 lec5)
其实现有算法里面除了bayesian算法,还有LDA和QDA很像生成模型,其他大部分都是送别模型。
生成模型得假设自变量的分布是有规律的,当然大部分就是gaussian分布。这样就会用用现有的数据估算自变量的模型,再用bayesian去计算条件概率,来进行边界决策。关键看P(x_n|y)
判别模型就没有这个估计,是什么就是什么。
从现在的算法来看,判别模型貌似居多,可能x符合gaussian的并不是很多。是不是可以先云自变量进行模型判定再选择模型呢?
在数据很多的情况下,其实判别模型可能更好,如果x真的很符合gaussian分布,数据也不多,那么生成模型可能更好。
* 注意 data noise很大,可能生成模型也不错,如收益率
抽样的有放回和无放回
用bagging做集成学习时,抽样是用的有放回抽样,boosting没有抽样这一步,每一轮的训练集不变,保是每轮中样本的权重发生了变化。
-
Bagging + 决策树 = 随机森林
-
AdaBoost + 决策树 = 提升树
-
Gradient Boosting + 决策树 = GBDT
bagging用在比较强,容易过拟合的模型上,比如决策树,为了降低variance boosting是可能过拟合的,用在容易欠拟合的模型上(当然这只是建议)
Ada boosting是对boosting的升级,基本原理一样,调整权重的算法不一样。一共有T轮,每轮的结果的权重又不一样,最后把T轮的结果加起来。
Ada boosting有一个神秘的现象,就是增加轮数后,train error已经不再将低了,但是test error还有可能继续降低。svm也有类似的效果。
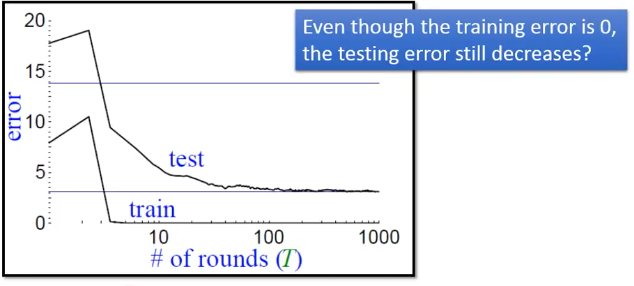
Gradient Boosting和boosting一样,也是每轮更新模型,但是要用Gradient Descent云minimize一个cost function。
svd
$$ A=U \Lambda U^{-1}=U \Lambda U^{T} $$ $$ \begin{aligned} A x_{1} &=\lambda_{1} x_{1} \\ A x_{2} &=\lambda_{2} x_{2} \\ & \ldots \\ A x_{m} &=\lambda_{m} x_{m} \end{aligned} $$ $$ U=\left[ \begin{array}{llll}{x_{1}} & {x_{2}} & {\cdots} & {x_{m}}\end{array}\right] $$ $$ \Lambda=\left[ \begin{array}{ccc}{\lambda_{1}} & {\cdots} & {0} \\ {\vdots} & {\ddots} & {\vdots} \\ {0} & {\cdots} & {\lambda_{m}}\end{array}\right] $$
上面是特征值分解(EVD),前提是A为对称陈,就是A等于A的转置。下面是针对任意矩阵的分解SVD
$$ A=U \Sigma V^{T} $$
其中A是M*N,U是m*m正交阵,E是M*N对角阵,V是n*n正交阵
SVD的统计意义就是PCA降维,特征重表示
降维
PCA的使用在实操篇里面已经讲得很好了,有一点我又实测了一下,就是关于PCA().components_,从原理分析,其实PCA只是做了坐标旋转,如果PCA不指定n_components参数的话,其实就是把坐标旋转后的所有信息都保存下来了,如果n_components等于2,那么就是提取前两个方差比较大的维度,数据和投影其实是一样的。
那么components_里面的东西倒底是什么呢?其实就是每个维度的主成分载荷,row是维度,如果取方差最大的维度就是components_[0]。
取了之后呢?可以把该维度的PCA数值算出来,和PCA().transform(X)出来的结果是一样的。公式具体可以参考 ISL中文 P158 6.19

tSNE 是基于模型的,当然大部分的资产收益率是接近 Gaussian 的,最多是用于可视化,可能降维效果一般般。
Autoencoder或许还不错
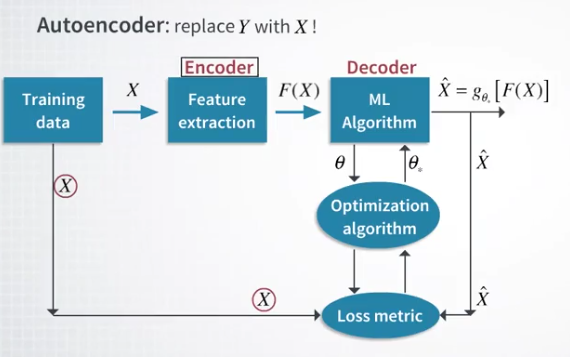
Autoencoder 是可逆的,encode 就是降维过程,decode是解码(升维)过程。PCA是特殊的线性Autoencoder模式。
用NN去寻找好的encoder,把decode出来的X~ 和原有的X进行对比,做一个cost function云进行优化
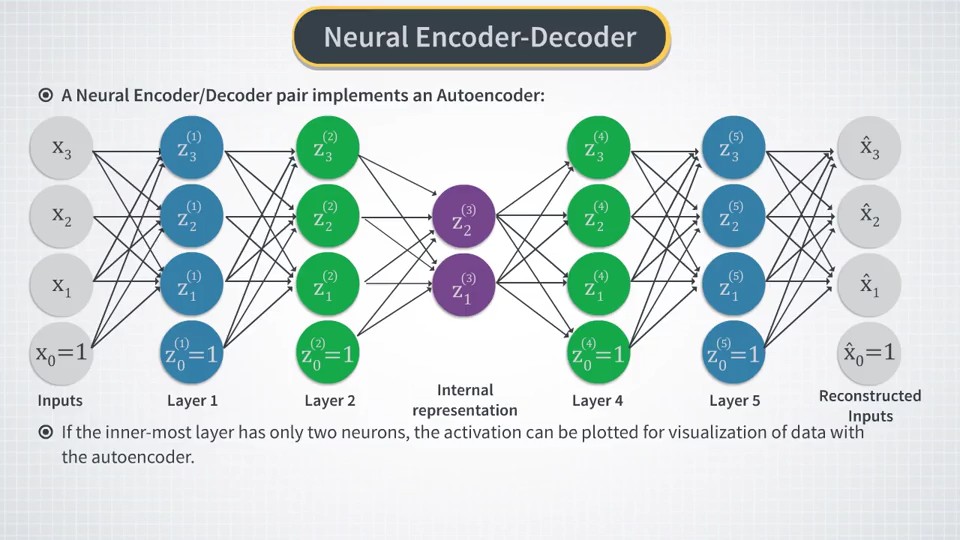
Latent Variables Model
中间出现个隐变量模型,对应的模型是LFM(Latent Factor Model),可能LFM是基于概率,而PCA不是的。LFM是interpret,PCA是represent。这个有空再细看吧。
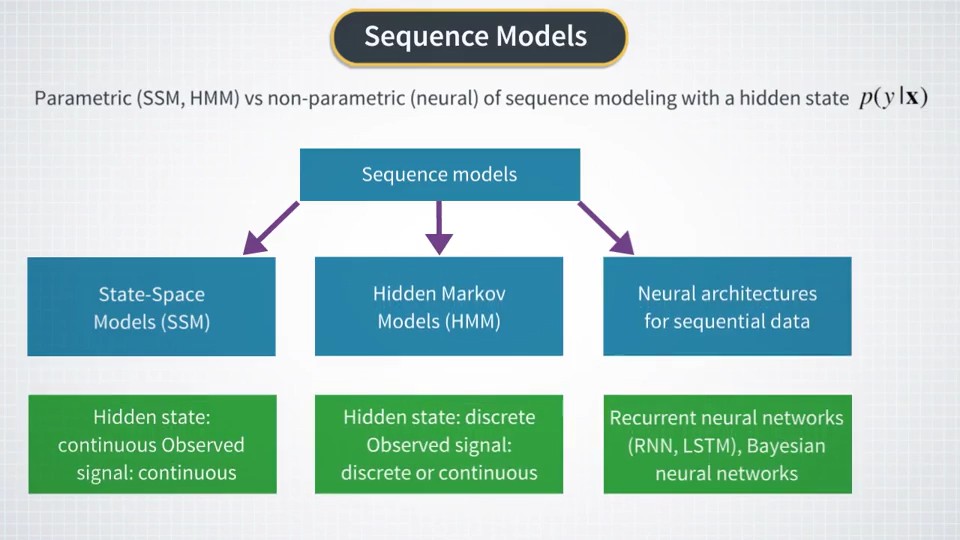
HMM
clustering
k++ mean 好于 k mean,数据标准化或者数据美白能帮助 这些算法,对于计算距离的算法,数据标准化是必需的。
下面是一些常用的距离算法:
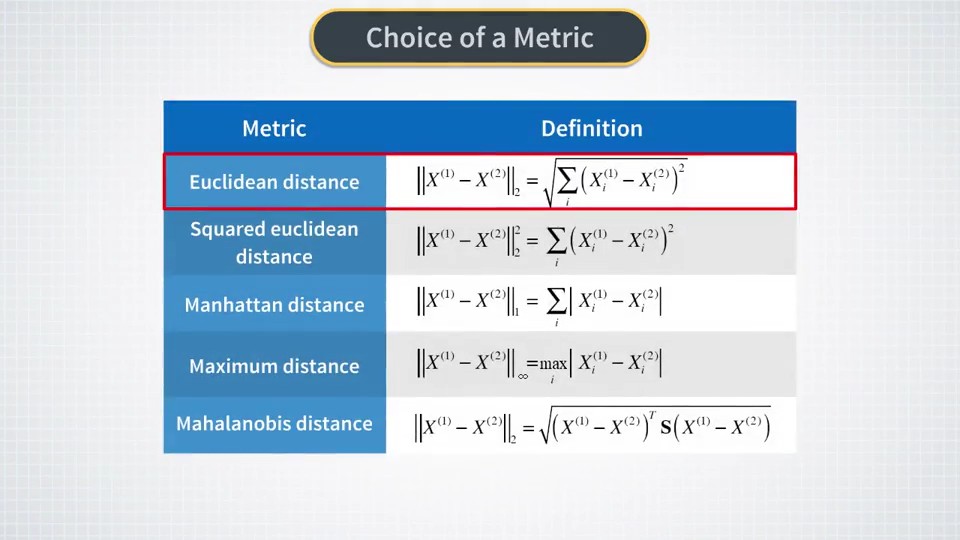
一些cluster之间的距离算法:

金融资产很多是多层结构,如板块划分,这个类聚用多层的类聚算法可能更好。Agglomerative Hierarchical Clustering
NLP
用这个主要是通过新闻,社交网络的信息(weibo,雪球等等)对涨跌的影响。
X:某时间段内或者某时间点的新闻(如果有人工标记会大幅提高性能)
Y:新闻出来后对应股价的涨跌
setp1: 分词(lib:jieba pip)
step2: 云掉停止词
step3: 用 1/N code 形成 vector,当然也可以用word2vec方法(更多可以参考lee hongyi 2007)
step4: - 求 P(y=1|x_n)(假设y=1代表上涨)
-
P(x_1|y=1) 把历史上涨的新闻(3000条)中x_1出现的次数(300次) = 300/3000
-
用bayesian定理就可求出 P(y=1|x_n)
tips:
- 一个文档值钱的词出现的词频是很低的,肥尾?所以可以把一些没有用的频次高的词去掉
- naive bayesian是NLP用到的东西,这里不细写,到处都有,其实就是求P(y=1|x_n),但是前提是x_i,x_j条件独立:P(x_i|y, x_j)=P(x_i|y) and P(x|y=1)=P(x_1|y=1)*P(x_2|y=1),这是典型的生成模型
- 建议不要从论坛,国家的政策比较有效,雪球还不错,tushare
- word2vec 假设30*300的矩阵,每一行是一个词,每行连起来就是一篇文章,再做CNN,CNN的Filter一定要覆盖300,整个宽度,因为一行是一个整体词,不可分割。疑问:CNN做NLP?
- 可自行维护对上涨或者下跌有影响的词库,自己做2vec,只用库里面的词,其他全当停止词扔掉
RL
强化学习分两类,一类是基于policy的,就是去learn一个actor(\(\pi \))直接告诉你做什么action,另一类是基于value(\(V(\pi )\))的,去learn一个actor告诉我们什么操作对应value是多少,当然value越大越好,还是越小越好,或者随机取对应的action,都是我们自己定的。
两种结合最好啦
带模型(model based)和不带模型(model free)
这里面最重要的就是模型是什么的模型? T[s,a,s'] state转换模型,R[s,a] reward模型
还记得gbm和ou过程吗?能否应用于此呢?嗯,得好好测测。
Q learning
Q learning是基于value的model free方法。
基于state做出action,转到下一个state,并获得reward。
state: 最值是要注意,不能直接取价格,因为价格从5~10块这样在12块时,机器无法做出决策,因为以前12块没出现过。一定要标准化,或者这种标准化方法:close/SMA
action: buy,shell,hold
reward: 直接用daily return会收敛的快一些,用总收益可能比较难算
然后就是state是连续值的问题,我想先把state分成间隔,用数字表示,再把所有的state组合在一块儿。比如 标准化后的close: 0.87 -> 9 , stdev: 34 ->7 ,组合就是97
Q是model free,是基于纯经验的,专家说效果不好,这个嘛得实测一下才行。
dyna
dyna 是model free和model based的混合模型,在Q的执行中会学习T和R,s'和r会从T和R中产生,再update Q table。
学T模型貌似就是:Sa往Sb转换的次数/总的转换次数 对的,就是一个转换概率
学习R模型请看 ML 4 trading udacity lec 27 Dyna,有一种简单的示例:\( R^{\prime}[s, a]=(1-\alpha) R[s, a]+\alpha \cdot r \)
一些比较有用的方法
DDPG,Dueling DQN,noisy net 请看Rainbow 这篇论文对RL中的一些方法都做了比对和combine。
A3C 是可以并行计算的混合模型,还可以处理连续问题,还不错,可以深入一下,请参考这篇文章
高级应用请再重看 lee hongyi RL ("Q-learning(Advanced Tips)")
cross validation
其实CV我反复看过好几次,也用到了,那么它的作用倒底是什么呢?
- 跑一次CV得出来的mse或者其他的判定方法的值更稳定,方差小,更准确
- mse更准确,这样做超参优化那就更准确了,对,超参优化
激活函数
貌似sigmoid已经不太看好了,用relu的居多
cost function
分类要用 cross entropy,其实logstic分类方法就是用的cross entropy,回归才用MSE类似的function。
而logstic可以想像成sigmoid网络里面的一个神经元。
sklearn
这个库确实是非常NB的,可惜现在不支持gpu,gpu主要是支持并行矩阵运算,如果把模型改到gpu可能成本过高。
这个库里面有minimize方法,很全的,如果自己写一些算法做优化可以直接用。
NN layer
一般来讲分类问题最后一层用softmax会好一些,因为它的输出在0~1之间,很像概率。
keras
keras 是 tensorflow 的封装,应该还是比较广,看一下最近出的一张图:
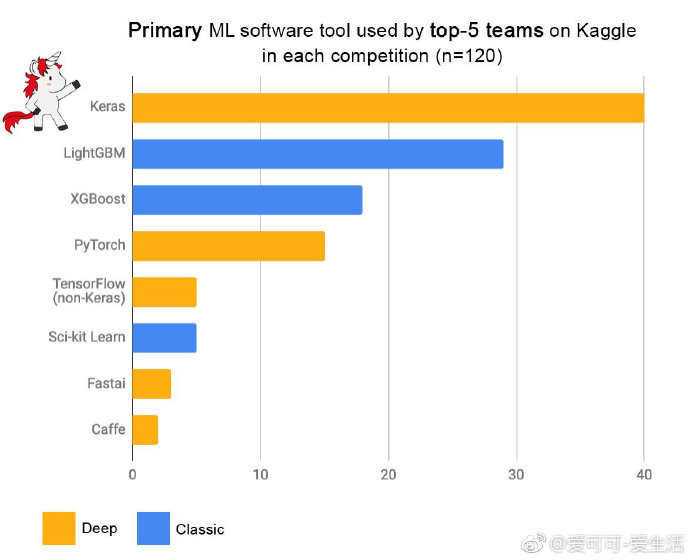
下面是一些应用技巧:
fit中的batch_size和nb_epoch
这就是实践和理论的差距,在实践DNN时其实是分批跑的,就是batch。
batch_size = 500,说明一个batch里面的sample是500个,至于有多少个batch,keras自动处理了,我也不知道具体算法。应该是数据量除以500取整+1吧,最后一个batch可能会少一点
epoch是什么呢?把整个batch跑过一轮叫一个epoch,一般跑个20epoch差不多了。
还有个参数叫shuffle,如果为true,则每次跑epoch前会把sample随机打乱。
tips
用类聚的方法先对目标进行分类或许是一个不错的方法
Exploit Explore
选餐厅:
- Exploitation : 去最喜欢的餐厅
- Exploration: 尝试新餐厅
挖石油:
- Exploitation : 继续挖已有的
- Exploration: 去新地方挖
在线广告:
- Exploitation : 展示最好的广告
- Exploration: 展示些不同的广告
B样条
分段低阶函数(bspline中4阶(最高3次幂)比较常用)连接来模拟曲线, 每段的函数是基函数的线性组合,基函数是一套,但是系数不一样,替代高阶函数,其实在ISL中的非线性模型中也有提到
bspline 用到的基函数是Cox - de Boor算法,ISL样条回归里面用到的是一些简单的多项式或者其他。
bspline同时也是一个pip库,在scipy里面也有实现
# https://github.com/johntfoster/bspline
X_min = 4.45
X_max = 66.78
p = 4 # order of spline (as-is; 3 = cubic, 4: B-spline?)
ncolloc = 12
# These are the sites to which we would like to interpolate
tau = np.linspace(X_min, X_max, ncolloc)
print("tau" ,tau)
# k is a knot vector that adds endpoints repeats as appropriate for a spline of order p
# To get meaningful results, one should have ncolloc >= p+1
k = splinelab.aptknt(tau, p)
basis = bspline.Bspline(k, p)
# 求出33.9的每个基上的系数
basis(33.9)
Comments
comments powered by Disqus